

Asembler 68k w przykładach - część 2
Na początku poprawimy błędy poprzedniego odcinka, które mimo moich najszczerszych chęci pojawiły się i mam nadzieję, że nie tylko ja je zauważyłem. Błędy pojawiły się na końcu trzybajtowego przykładu zarówno w wersji oszczędnej i w wersji wielolinijkowej. Tam gdzie miała być wartość 16 we wszystkich trzech bajtach, to była tylko w dwóch pierwszych ostatni był 15. Poprawny przykład w wersji jednolinijkowej
dc.b 16,%1000,$10
Za błędy przepraszam i będę bardziej wnikliwie czytał odcinki pod kątem takich błędów.
WSTĘP
W tym odcinku skupimy się na przede wszystkim na pamięci. Wspomnimy trochę o układach specjalizowanych. Poznamy nowe komendy i dyrektywy Asm-One, a wszystko to okrasimy przykładami.
PAMIĘĆ
Z poprzedniego odcinka potrafimy zapisać gdzieś w pamięci pojedynczy bajt, sekwencje bajtów czy to w postaci słowa, długiego słowa czy też zwyczajnie jako ciąg bajtów. Korzystamy wtedy z dyrektywy asemblera dc. Wpisywanie dużej ilości bajtów jest z pewnością czasochłonne, łatwo o pomyłkę i najważniejsze zajmuje sporo miejsca w kodzie źródłowym. Jeśli jesteśmy już przy rozmiarach, to aby łatwiej operować większymi ilościami bajtów, zdefiniujemy jednostki
Wciąż nie wiemy gdzie dokładnie zostały zapisane bajty. Wspomniałem też o tym, że procesor komunikuje się z pamięcią, która jest ponumerowana, a owe numery to adresy. Jasne jest, że jest ona skończona, posiada początkowy adres 0 i końcowy, który jest zależny od tego ile jej posiadamy.
Dla przykładu, gdy mamy tylko cztery bajty pamięci, to łatwo możemy podać wszystkie możliwe adresy. Są to: zero, jeden, dwa i trzy. Czyli, jeśli mamy pamięć wielkości 4 bajtów, to nie pojawia się adres o numerze 4, bo zawsze liczymy od zera.
A gdy posiadamy 64 kilobajty pamięci (64 * 1024 bajty) to ostatnia komórka pamięci będzie miała adres 65535 ($ffff). Adres ten będzie 16-bitowy, bo za pomocą tylu bitów jesteśmy w stanie, w precyzyjny sposób określić położenie każdej komórki pamięci (każdego bajtu). Pytanie powinno nasunąć się samo, a dlaczego autor wybrał 64 kilobajty, przecież mógł wybrać 100 bajtów i wtedy, byłoby jasne że ostatni bajt ma numer 99 licząc od zera. Oczywiście że można tak wybrać, ale w świecie komputerów wszystko się kręci wokół liczb dwójkowych. W tym przypadku mamy do czynienia z maksymalną daną liczbą binarną (liczbą złożoną z samych jedynek), która określa maksymalną wielkość pamięci. W naszym przykładzie jak łatwo się domyślić będzie to szesnaście jedynek dwójkowo 1111111111111111. By dowiedzieć jak to jest w MC68000, musimy wiedzieć coś więcej o połączeniu procesora z pamięcią. Nazywamy je szyną adresową, która umożliwia w jednoznaczny sposób określić bajt w pamięci. Motorola 68000 ma szynę adresową 24 bitową, czyli może zaadresować 24 bitowy adres. To daje możliwość obsługi pamięci o wielkości 16 megabajtów.
Asm-One umożliwia nam podejrzenie i modyfikowanie pamięci komendą h bądź H, ja z przyzwyczajenia będę pisał za pomocą małej litery. Wchodzi on wtedy w tryb Monitor, który z kolei może mieć trzy postacie: deasemblacja kodu, kody ascii i pokazywanie danych w formie szesnastkowej reprezentacji.
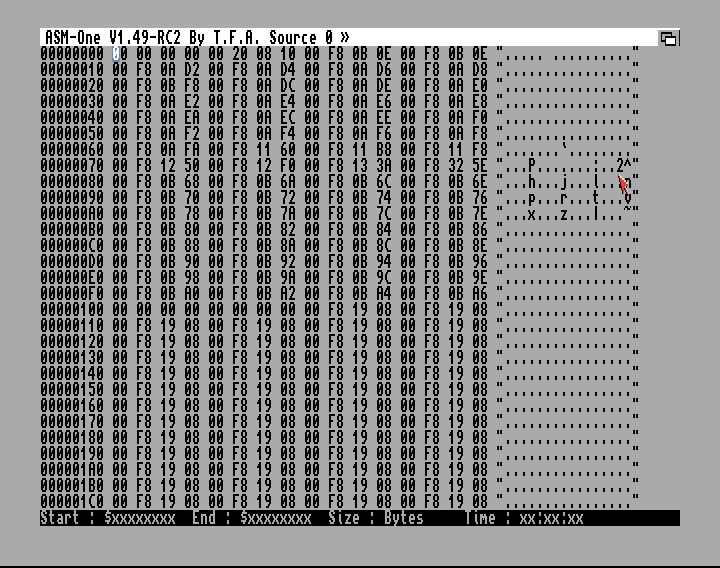
W tym ostatnim widzimy z lewej strony adres, który jest liczbą 32 bitową zapisaną jako szesnastkowa a potem szesnaście kolumn z bajtami. Wpisując pierwszy raz komendę h pokazywany jest zrzut pamięci od adresu zero, czyli od początku. Zmieniamy to wpisując na przykład h $70000 i wtedy będzie widoczna pamięć od adresu $70000. Asm-One zapamiętuje ten adres i jeśli wyjdziemy klawiszem esc a potem ponownie wpiszemy tylko samo h, to zostanie użyty adres ostatnio wpisany. Kursorami do góry i do dołu przesuwamy się odpowiednio o wiersz (16 bajtów) do góry bądź do dołu. A gdy mamy wciśnięty Alt to strzałkami lewo/prawo przesuwamy adres o jeden bajt. Co ciekawe, możemy zmieniać kolumny z bajtów na słowa i długie słowa, co spowoduje, rzecz jasna, zmniejszenie ilości kolumn, do tego celu używamy albo odpowiedniej komendy albo skrótu klawiszowego.
Pokazywanie pamięci jako słowa ma ograniczenie do adresów parzystych - procesory 68020 i wyższe już pozwalają na to. W przypadku próby pokazywania słowa jako adresu nieparzystego zostanie wygenerowany błąd.
Oprócz podglądania możemy także zmieniać stan pamięci - wystarczy najechać na interesujący nas adres i zmodyfikować wartość. Należy zachować ostrożność, bo pamięć jest w dynamiczny sposób używana przez system operacyjny i możemy narobić niezłego bigosu. Z pewnością każdy wymyśli przynajmniej parę przykładów z komendą h, ja ograniczę się do problemów, które mogą się pojawić. Najczęściej spotykany to próba pokazania pamięci w formie słów bądź długich słów od nieparzystego adresu. Są jeszcze inne błędy związane z odczytem bądź zapisem określonych obszarów pamięci, ale do tego jeszcze dojdziemy.
ETYKIETY
Załóżmy że mamy kod umiejscowiony pod adresem $10000, to możemy go teraz przedstawić w następujący sposób.
00010000 dc.w $4e75 ;rts
Z samej lewej strony pojawił się tenże adres, zapisany jako wartość szesnastkowa długiego słowa, z wiodącymi zerami a potem mamy znaną nam dyrektywę dc i dalej komentarz. W bardzo prosty sposób możemy dowiedzieć się jaki jest adres następujący po dyrektywie dc.w. Wystarczy dodać 2 (bo tyle bajtów zajmuje słowo). Ale czy możemy być pewni, jaki będzie przed nim? Jeśli przedstawiamy pamięć w formie słów to tu sprawa jest jasna, wystarczy odjąć dwa. Z kodem to już nie jest to takie oczywiste, gdyż mnemoniki zajmują niekoniecznie tylko dwa bajty.
Nie proponuję asemblacji powyższego przykładu, gdyż on tylko ma pokazywać pod jakim adresem kod może się znajdować, i zapewniam, że się nie skompiluje. W takim razie jak mamy się dowiedzieć, gdzie został skompilowany kod skoro nie mamy jeszcze żadnego odniesienia? Tu dochodzimy do nowego pojęcia jakim jest etykieta. Dzięki niej nadajemy adresowi specjalną nazwę. Oto i minimalny przykład
start:
Należy skompilować ten przykładzik (komenda a) i użyć komendy ?start.
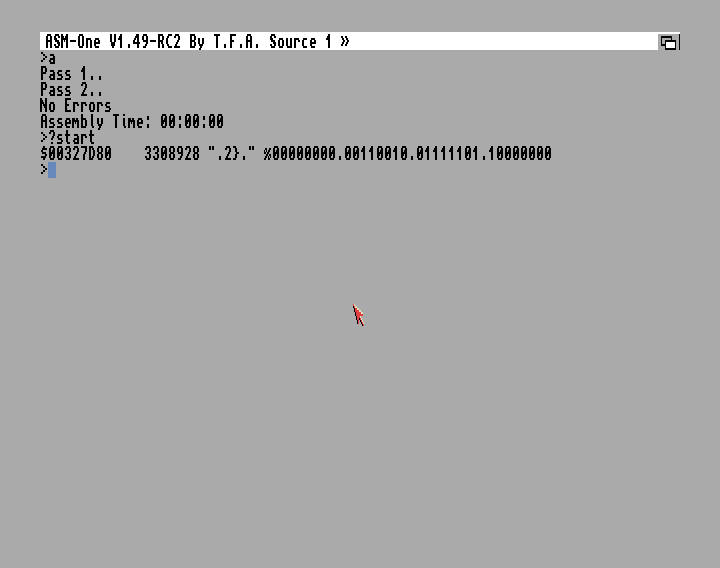
Etykieta (Label) przeważnie zaczyna się od początku linii i może kończyć się dwukropkiem. Napisałem przeważnie, bo widziałem źródła, gdzie jest inaczej. Lecz wtedy musimy mieć zaznaczoną opcję 'Label :' w ASM-One Assembler Preferences (Prawa Amiga + ]). Ja osobiście wolę umieszczać etykietę na początku linii. Wtedy to pierwszy biały znak (spacja, tabulator, enter) oznaczają jej koniec. Jasne jest że etykieta nie może zaczynać się od znaku komentarza (; bądź *), bo wtedy mamy linię komentarza. A gdy zwiera w sobie znak komentarza, to wtedy asembler podczas kompilacji przytnie nazwę etykiety. Warto to sprawdzić pisząc:
star?t:
i po skompilowaniu użyć komendy ?start.
Nazwa etykiety podlega ograniczeniom: Nie powinna ona być rozkazem procesora bądź innym zarezerwowanym słowem, bo wtedy powstanie problem rozróżnienia co jest etykietą a co nie. Pierwszym znakiem etykiety musi być litera bądź znak podkreślenia. W ten sposób właśnie definiujemy etykietę globalną, czyli widoczną w całej źródłówce.
Oto przykłady takich etykiet
etykieta: mojaEtykieta InnaEtykieta: _jeszcze_inna_etykieta
A jeśli zaczniemy nazwę od kropki, uzyskamy wtedy etykietę lokalną, która to powinna być tworzona po etykiecie globalnej. Innymi słowy nie możemy utworzyć lokalnej etykiety na samym początku źródła. Zasięg takiej etykiety, czyli widoczność, jest ograniczona do bloku pomiędzy najbliższymi etykietami globalnymi, oznacza to że nazwy etykiet lokalnych mogą się powtarzać, oczywiście nie w tym samym bloku.
Przykłady etykiet zarówno lokalnych jak i globalnych.
a10: .as: sl00n Start: .loop
Wśród typowych problemów, jakie mogą się przydarzyć w związku z etykietami, najpopularniejszym jest błąd podwójnego symbolu. Nie można nadać tej samej nazwy dla dwóch etykiet, nawet jeśli odnoszą się one do tego samego adresu, czyli taki przykład jest błędny
start: start: rts
I ten także
game: rts rts game: nop rts
A ten przykład jest poprawny, mimo że są dwie takie same etykiety .ety
start: nop .ety nop nop rts start2: .ety rts
Asemblery mają zdefiniowaną maksymalną długość dla etykiety i jeśli zostanie ona przekroczona, to wtedy może pojawić się błąd podwójnego symbolu.
Pojawić się może też błąd: Illegal operator, gdy będziemy próbowali utworzyć nazwę zawierającą niedozwolony znak.
Gdy mamy zaznaczoną opcję UCase = LCase (nie rozróżniaj dużych i małych liter) w konfiguracji, to wtedy ten przykład jest błędny
traktor: dc.w 0 TrAkToR: dc.w 1
Nic nie stoi na przeszkodzie, aby dwie lub więcej etykiet odnosiło się do tej samej lokacji.
start1: start2: rts
By to sprawdzić należy użyć komendy ?start1 i ?start2.
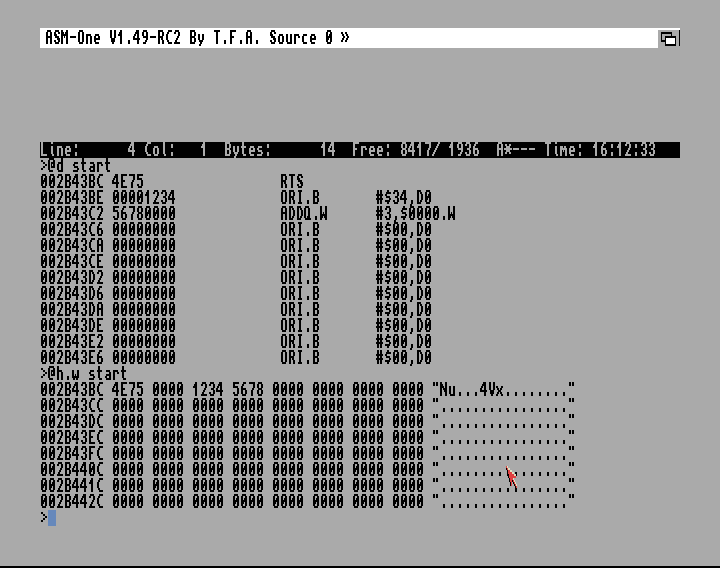
Skoro znamy etykiety i wiemy co nieco o pamięci, to przekonajmy się gdzie został zapisany ten przykład
Start: rts
Wystarczy zasemblować przykład i użyć komendy ?Start. Można do tego celu użyć także @d adres, gdzie adres to będzie nazwa etykiety.
BLOKI PAMIĘCI
We wszystkich przykładach, widzimy nieduże ilości danych. A gdybyśmy chcieli stworzyć na przykład 1000 bajtów i każdy z nich o wartości 1, to co wtedy? Mamy mozolnie wpisywać te wszystkie dc.b 1 bądź też dc.l $01010101? Na szczęście Asm-One umożliwia nam definiowanie bloków danych. Z pomocą przychodzi dcb.x ilość, wartość, gdzie x - to b,w bądź l.
dcb.b 1000,1
Możemy też pominąć przyrostek i wtedy będzie to 1000 słów. Co ciekawe możemy pominąć też wartość i wtedy zostanie nadana wartość zero. Przeglądając różne źródłówki możemy trafić na dyrektywę blk.x, która oznacza dokładnie to samo co dcb.x a zachowana jest dla kompatybilności ze starszymi asemblerami.
Przykłady
dcb.l 8,$02020202 ;8 długich słów, które odpowiadają 16 słowom bądź 32 bajtom dcb.w 16,$0202 dcb.b 32,$02 dcb.b 20,-1
Błędy, które możemy spotkać to problem wyrównania, czyli definiowanie bloku słów bądź długich słów od nieparzystego adresu. Wówczas ujrzymy komunikat **Word at ODD Address. Uwaga - nawet jeśli mamy ustawiony w konfiguracji asemblera CPU na 68020, to i tak zobaczymy ten komunikat.
WYRÓWNYWANIE PAMIĘCI
Najprostszy sposób na wyrównanie pamięci do dodanie tylu bajtów, ile potrzebujemy aby je uzyskać. Niestety w niektórych przypadkach będzie to uciążliwe, szczególnie gdy wprowadzamy częste zmiany. Do wyrównywania pamięci służą trzy dyrektywy: CNOP ilość, wyrównanie, EVEN, ODD. Pierwsza wyrównuje adres do wyrównania a potem dodaje do tego adresu ilość. Druga koryguje adres do parzystego. A jak łatwo się domyśleć ostatnia wyrównuje do nieparzystego. Dwie ostatnie można uzyskać za pomocą CNOP, ale wygodniej jest napisać jedno słowo. Przykłady
CNOP 0,4 ;wyrównanie do długiego słowa, czyli adres będzie podzielny przez 4 Dane0: dc.b 0,1,2 EVEN ;do słowa, czyli parzysty adres Dane1: dc.b 5 CNOP 0,2 ;to samo co EVEN Dane2: dc.b 7,1 CNOP 1,2 ;to samo co ODD, czyli Dane3 będzie nieparzystym adresem Dane3: dc.b 9
Dodajmy, że jeśli adres jest już parzysty to dyrektywa EVEN nie zmieni adresu. Małym mankamentem, w przypadku gdy wyrównujemy wiele adresów nieparzystych, jest utrata bajtów, co w produkcjach, gdzie liczy się każdy bajt, nie jest wskazane. Poza tym nie ma kontroli nad wartością bądź wartościami bajtów, które zostały użyte do korekcji adresu.
ZAPIS I ODCZYT PAMIĘCI
Jeśli chcemy zapisać blok pamięci na dysku w postaci pliku binarnego, to korzystamy z komendy WB nazwa, gdzie nazwa oznacza nazwę pliku. Nie podając nazwy zostanie wyświetlona "wybieraczka" plików. Następnie podajemy początek obszaru a potem jego koniec. Podobnie jest przy odczycie pliku do pamięci, tyle że używamy komendy RB nazwa. Zdziwienie może budzić, że musimy podać koniec obszaru przy odczycie pliku, ale wszystko stanie się jasne, gdy zechcemy wczytać początkowy kawałek pliku.
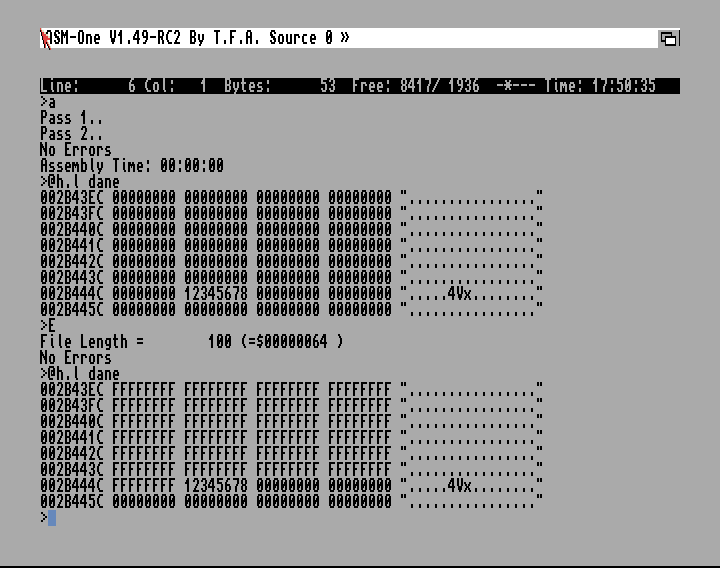
Z poziomu kodu źródłowego mamy do dyspozycji INCBIN nazwa i >EXTERN [numer],nazwa,adres,[długość]. Pierwszy z nich, ładuje dane z pliku, robione jest to za każdym razem, gdy asemblujesz projekt, co ma i plusy i minusy. Druga dyrektywa wczytuje plik o nazwa pod adres - opcjonalnie można długość i podać numer, który przyda się przy komendzie E [numer]. Ta komenda powoduje, że dopiero wtedy wczytywany jest plik. Musimy najpierw zasemblować projekt, a potem, jeśli chcemy, to używamy komendy E. W podanym przykładzie załóżmy, że mamy plik binary o długości 100 bajtów.
dane: incbin 'ram:binary' koniecdanych:
Wtedy po asemblacji, gdy wykonamy ?koniecdanych-dane, otrzymamy oczekiwany wynik 100. Ponadto używając dyrektywy h dane ujrzymy dane z pliku.
dane: dcb.b 100,0 >EXTERN 0,'ram:binary',dane,100
A w tym przypadku po asemblacji będziemy mieli 100 bajtów o wartości 0. A po użyciu komendy E będą to dane z pliku. Ja stworzyłem taki plik, gdzie wszystkie 100 bajtów ma wartość $ff, co jest łatwe do wykonania i pozostawiam to jako łatwe ćwiczenie. Jak widać na obrazku, taki był rezultat przed i po użyciu tej komendy.
PAMIĘĆ I UKŁADY SPECJALIZOWANE
Oprócz pamięci i procesora, Amiga została wyposażona w układy specjalizowane, które zaprojektowano do realizacji określonych zadań, takich jak generowanie dźwięku, kopiowanie bloków pamięci. Ale jak się z nimi komunikować? Dobrze byłoby gdyby za pomocą procesora nakazać coś zrobić takiemu układowi. Do tego celu służą specjalne obszary pamięci. Zapisując bądź odczytując je komunikujemy się z tymi układami. W tym przypadku komórki pamięci czy to w postaci bajtu, słowa bądź długiego słowa nazywamy rejestrem układu specjalizowanego. Czyli rejestry te są zmapowane w przestrzeni adresowej naszego procesora. Na przykład bit 6 w $bfe001 przechowuje informacje o stanie lewego przycisku myszy w porcie numer 0. Zwróćmy uwagę że nie informujemy w jakiś specjalny sposób procesora, że teraz chcę komunikować się z takim układem, tylko wystarczy zapisać czy też odczytać tę informacje z odpowiedniego obszaru pamięci. Tu dochodzimy do dwóch wniosków. Po pierwsze - Amiga z szyną 24 bitową na pewno nie ma 16 megabajtów przeznaczonych dla użytkownika, bo część zajmują rejestry układów specjalizowanych. A po drugie, żeby programować pod hardware trzeba znać rejestry i wiedzieć, co do nich wkładać bądź co oczekiwać przy ich czytaniu. Kolejna bardzo ważna rzecz, niektóre rejestry zostały tak zaprojektowane, że można je tylko odczytać bądź tylko zapisać, co oznacza, że pewnych obszarów pamięci nie można podejrzeć a innych nie można modyfikować. Skutkować to może przykrymi konsekwencjami, przykładowo wpisując komendę h $dff180 spowodujemy zawieszenie naszej przyjaciółki.
RODZAJE PAMIĘCI
Skoro różne układy dzielą pamięć, to w naturalny sposób można mówić o typach pamięci. Oto schematyczny podział pamięci:
Sytuacja jest teraz trochę zagmatwana. Co z tego że mamy pamięć, procesor i układy specjalizowane, skoro teraz komunikacja się komplikuje i jeśli jakiś układ "rozmawia" z pamięcią, to procesor musiałby czekać. Aby zminimalizować proces czekania, wprowadzono kontroler DMA, który odciąża procesor. Pomaga on układom specjalizowanych dzielić się czasem z procesorem przy dostępie do pamięci, którą to nazywamy CHIP, komunikacja odbywa się za pomocą 16 bitowej bądź 32 bitowej szyny w zależności od Amigi. Do dyspozycji mamy adresy od $00000000 - $001fffff w zależności od posiadanego chipsetu (OCS/ECS/AGA). Pamięć FAST jest dostępna tylko przez procesor, co skutkuje przyrostem szybkości. Wskutek ograniczeń od $c00000 mamy pamięć niechlubnie nazywaną SLOW, z tego względu, że układy specjalizowane nie mają tam możliwości jej używania, a muszą ją dzielić z procesorem. Na początek wystarczy znać dwa rodzaje pamięci: CHIP i FAST. Dla twórcy, programującego pod hardware najważniejsza będzie właśnie pamięć CHIP, której zawsze jest za mało.
W następnym odcinku poznamy chyba najczęściej używany mnemonik move i nadgryziemy temat rejestrów procesora.

