


11.12.2018 23:41
[#424]
Re: A500 Turbo ..... inaczej
@Cizar, post #416
W AGA i A3000 magistrala dla CPU jest 32 bit, a generalnie w ECS/OCS 16 bit (poza A3000). W AGA taktowanie pamięci Chip jest 14 MHz podczas gdy w starszych kościach 7 MHz. To m.in. pozwala na to, by układy specjalizowane w architekturze AGA pobierały dane z pamięci Chip po 64 bity przy jednym odczycie (sterowane rejestrem FMODE). Niestety na CPU FMODE wpływu nie ma 
Niezależnie od szerokości magistrali wąskim gardłem jest taktowanie cykli DMA, które dla wszyskich układów OCS/ECS/AGA wynosi 3,5 MHz/cykl, a to oznacza, że każdy odczyt/zapis do pamięci Chip wykonywany przez CPU (nawet jeśli 32 bitowy) powoduje de facto zatrzymanie CPU do momentu przydzielenia kanału DMA i zakończenia docelowej operacji.
Tego nie przeskoczymy, taka architektura i trzeba z tym żyć... ale... moim zdaniem istnieje światełko w tunelu, które potencjalnie można by wykorzystać w tym konkretnym przypadku, a mianowicie właśnie grafice 3D (chunky), choć nie tylko... odtwarzanie strumieniowanego audio np. z plików MP3 wymaga działania na podobnych zasadach.
Analizując charakterystykę dostępu do pamięci Chip przez gry i dema wykorzystujące grafikę 3D na klasycznych układach (chunky2plannar) czy odtwarzanie strumieniowanego audio, dosyć łatwo zauważyć, że od strony CPU to właściwie zawsze mówimy tylko i wyłącznie o odczycie z pamięci Fast i zapisie do pamięci Chip. Oczywiście powstały pewne triki i obejścia minimalizujące straty czasu CPU jak choćby c2p do Fast, a następnie kopiowanie Fast->Chip przy wyłączonym DMA bitplane'ów (żeby teoretycznie zwiększyć przepustowość DMA dla CPU podczas tej operacji), ale co Wy na to, gdyby przy okazji konstruowania kart przez CS-LAB możliwe było wprowadzenie buforowania zapisu do pamięci Chip, gdzie CPU zapisywał by dane wyłącznie do bufora, a faktyczne kopiowanie bufor->Chip Ram było realizowane bez angażowania CPU? Takie rozwiązanie nie wymagało by ingerencji w płytę główną w celu bezpośredniego dostępu do pamięci Chip przez dedykowany kanał, a dodatkowo kultywowało by podejście, które od początku przyświecało konstruktorom Amigi czyli przekazywanie zadań specjalizowanych do dedykowanych układów zwalniając CPU od nadzorowania tych czynności.
Wyobrażam sobie to mniej więcej tak, że między CPU, a DMA jest postawiony kolejkowany bufor 'write only' do pamięci Chip. Każdy zapis CPU->Chip Ram kończy się w tym buforze (oczywiście z zachowaniem taktowania procesora, a nie taktowania DMA), dzięki czemu CPU lata z maksymalną prędkością również podczas zapisu do Chip (co prawda wirtualnego - czyli nie trafiającego do prawdziwej pamięci Chip, a do bufora), ale dzięki temu CPU w Amidze może po szerokości rozwinąć skrzydła, bo wszystkie operacje zapisu do pamięci (niezależnie od jej typu) realizowane są z maksymalną wydajnością... Z tym, że potrzebny jest kolejny element, a mianowicie coś co będzie działać pomiędzy kolejkowanym 'write only' buforem Chip, a DMA i tutaj już standardowo, pobranie najstarszego zapisu z kolejki, czekanie na slot, zapis, ale dziejące się całkowicie poza CPU. Jedyny stall CPU w takiej sytuacji dotyczył by wyłącznie konieczności odczytu przez CPU z Chip Ram - ale przecież takie operacje nie mają sensu
Fajnie? Fajnie, fajnie... tylko czy jest możliwość by taką logikę zaimplementować w FPGA na kartach spod szyldu CS-LAB? Pewnie trzeba by zapytać Andrzeja... Cizar załatwisz temat?
Taka konstrukcja na pewno najwięcej dałaby przy procesorach 060, gdzie procesor w operacjach zapisu do Chip bardzo mocno jest dławiony przez tzw. Copyspeed, ale nawet karty ze znacznie słabszymi procesorami mogłyby z tego mechanizmu efektywnie korzystać - wszystko kwestia odniesienia do konkretnego przypadku.
Rozpisując ten koncept w trzech krokach (w odniesieniu do 3D na układach klasycznych):
1. kalkulacja sceny (Fast->CPU->Fast) - tu wydajność zapewnia DDR3
2. c2p (Fast->CPU->Chip buffer) - jeśli Chip buffer w DDR3 to oczywiście też petarda jak wyżej
3. swapBuffers (CPU->Chip buffer) - zapis nowego adresu bitplaneów do wyświetlenia (wykona się zawsze po c2p więc synchronizacja jest zapewniona)
4. goto 1
A równolegle do operacji powyżej chodzi sobie w FPGA proces (FIFO Chip buffer->DMA->Chip Ram)...
PS: Zauważcie jaką w tej architekturze porażką konstrukcyjną wydaje się być Akiko, które przy 3D działa tak: Chip->Akiko(c2p)->Chip i każda operacja na slotach DMA... Jednak Akiko działa na gołej CD32 czyli 020 bez Fast'u, a to już może się jako tako kalkulować
Niezależnie od szerokości magistrali wąskim gardłem jest taktowanie cykli DMA, które dla wszyskich układów OCS/ECS/AGA wynosi 3,5 MHz/cykl, a to oznacza, że każdy odczyt/zapis do pamięci Chip wykonywany przez CPU (nawet jeśli 32 bitowy) powoduje de facto zatrzymanie CPU do momentu przydzielenia kanału DMA i zakończenia docelowej operacji.
Tego nie przeskoczymy, taka architektura i trzeba z tym żyć... ale... moim zdaniem istnieje światełko w tunelu, które potencjalnie można by wykorzystać w tym konkretnym przypadku, a mianowicie właśnie grafice 3D (chunky), choć nie tylko... odtwarzanie strumieniowanego audio np. z plików MP3 wymaga działania na podobnych zasadach.
Analizując charakterystykę dostępu do pamięci Chip przez gry i dema wykorzystujące grafikę 3D na klasycznych układach (chunky2plannar) czy odtwarzanie strumieniowanego audio, dosyć łatwo zauważyć, że od strony CPU to właściwie zawsze mówimy tylko i wyłącznie o odczycie z pamięci Fast i zapisie do pamięci Chip. Oczywiście powstały pewne triki i obejścia minimalizujące straty czasu CPU jak choćby c2p do Fast, a następnie kopiowanie Fast->Chip przy wyłączonym DMA bitplane'ów (żeby teoretycznie zwiększyć przepustowość DMA dla CPU podczas tej operacji), ale co Wy na to, gdyby przy okazji konstruowania kart przez CS-LAB możliwe było wprowadzenie buforowania zapisu do pamięci Chip, gdzie CPU zapisywał by dane wyłącznie do bufora, a faktyczne kopiowanie bufor->Chip Ram było realizowane bez angażowania CPU? Takie rozwiązanie nie wymagało by ingerencji w płytę główną w celu bezpośredniego dostępu do pamięci Chip przez dedykowany kanał, a dodatkowo kultywowało by podejście, które od początku przyświecało konstruktorom Amigi czyli przekazywanie zadań specjalizowanych do dedykowanych układów zwalniając CPU od nadzorowania tych czynności.
Wyobrażam sobie to mniej więcej tak, że między CPU, a DMA jest postawiony kolejkowany bufor 'write only' do pamięci Chip. Każdy zapis CPU->Chip Ram kończy się w tym buforze (oczywiście z zachowaniem taktowania procesora, a nie taktowania DMA), dzięki czemu CPU lata z maksymalną prędkością również podczas zapisu do Chip (co prawda wirtualnego - czyli nie trafiającego do prawdziwej pamięci Chip, a do bufora), ale dzięki temu CPU w Amidze może po szerokości rozwinąć skrzydła, bo wszystkie operacje zapisu do pamięci (niezależnie od jej typu) realizowane są z maksymalną wydajnością... Z tym, że potrzebny jest kolejny element, a mianowicie coś co będzie działać pomiędzy kolejkowanym 'write only' buforem Chip, a DMA i tutaj już standardowo, pobranie najstarszego zapisu z kolejki, czekanie na slot, zapis, ale dziejące się całkowicie poza CPU. Jedyny stall CPU w takiej sytuacji dotyczył by wyłącznie konieczności odczytu przez CPU z Chip Ram - ale przecież takie operacje nie mają sensu
Fajnie? Fajnie, fajnie... tylko czy jest możliwość by taką logikę zaimplementować w FPGA na kartach spod szyldu CS-LAB? Pewnie trzeba by zapytać Andrzeja... Cizar załatwisz temat?
Taka konstrukcja na pewno najwięcej dałaby przy procesorach 060, gdzie procesor w operacjach zapisu do Chip bardzo mocno jest dławiony przez tzw. Copyspeed, ale nawet karty ze znacznie słabszymi procesorami mogłyby z tego mechanizmu efektywnie korzystać - wszystko kwestia odniesienia do konkretnego przypadku.
Rozpisując ten koncept w trzech krokach (w odniesieniu do 3D na układach klasycznych):
1. kalkulacja sceny (Fast->CPU->Fast) - tu wydajność zapewnia DDR3
2. c2p (Fast->CPU->Chip buffer) - jeśli Chip buffer w DDR3 to oczywiście też petarda jak wyżej
3. swapBuffers (CPU->Chip buffer) - zapis nowego adresu bitplaneów do wyświetlenia (wykona się zawsze po c2p więc synchronizacja jest zapewniona)
4. goto 1
A równolegle do operacji powyżej chodzi sobie w FPGA proces (FIFO Chip buffer->DMA->Chip Ram)...
PS: Zauważcie jaką w tej architekturze porażką konstrukcyjną wydaje się być Akiko, które przy 3D działa tak: Chip->Akiko(c2p)->Chip i każda operacja na slotach DMA... Jednak Akiko działa na gołej CD32 czyli 020 bez Fast'u, a to już może się jako tako kalkulować
12.12.2018 09:27
[#425]
Re: A500 Turbo ..... inaczej

@dante, post #424
Pomysł fajny i ciekawy, ale przecież na kartach będzie GFX i tam nie będzie problemu z przepustowością. A pozostałe gry i programy na OCS nie wymagają jakiś strasznych transferów, więc wydaję się, że troszkę szkoda pracy chłopaków.
Aby dalej zoptymalizować c2p, obliczenia wykonuje się normalnie, ale kopiowanie danych do CHIP najlepiej wykonywać po wygaszaniu pionowym (uruchamiane przełącznikiem z przerwania). Uzyskuje się w tedy najwyższy transfer, sporo większy niż teoretyczny transfer FAST->CHIP, gdyż właśnie DMA nie pobiera obrazu i (o ile Blitter nie pracuje) cały dostęp jest dla CPU.
Aby dalej zoptymalizować c2p, obliczenia wykonuje się normalnie, ale kopiowanie danych do CHIP najlepiej wykonywać po wygaszaniu pionowym (uruchamiane przełącznikiem z przerwania). Uzyskuje się w tedy najwyższy transfer, sporo większy niż teoretyczny transfer FAST->CHIP, gdyż właśnie DMA nie pobiera obrazu i (o ile Blitter nie pracuje) cały dostęp jest dla CPU.


12.12.2018 10:42
[#427]
Re: A500 Turbo ..... inaczej
@flops, post #425
Pisząc o c2p do Fast i kopiowaniu do Chip przy wyłączonym DMA bitplane'ów dokładnie to miałem na myśli. Nie jest to do końca przerwanie wygaszania pionowego, tylko przerwanie generowane 'ręcznie' po ostatniej linii obrazu np. dla obrazu 320x200 generuje się je na końcu rasterlinii wyświetlającej 200tną linię obrazu, dla 320x180 na końcu rasterlinii wyświetlającej 180tą linię obrazu, wyłączając przy okazji w tym momencie DMA bitplane'ów.
W PAL obraz ma 312 rasterlinii więc tą techniką uzyskuje się ok. 112-132 rasterlinii, w czasie których wykonuje się kopiowanie Fast->Chip. Transfer w tym czasie Fast->CPU->Chip określany jest jako 3xCopyspeed ponieważ dla CPU w tym czasie dostępnych jest więcej slotów DMA. Niestety nadal są to sloty taktowane 3,5MHz, a biorąc pod uwagę, że zapis do Chip wymaga dwóch cykli DMA (1 adresowanie, 2 zapis) to efektywna częstotliwość zapisu do Chip jednego długiego słowa (32 bit) jest jeszcze o połowę mniejsza niż taktowanie slotów DMA.
Jednak największym problemem z punktu widzenia CPU jest to, że w tym czasie CPU nie może robić nic innego jak tylko kopiowanie Fast->Chip, a jest to mniej więcej 30-40% czasu ramki! To są bardzo duże straty na wydajności procesora i wydaje się, że przedstawiony przeze mnie pomysł pozwoliłby całkowicie wyeliminować te straty.
Oczywiście na kartach od CS-LAB ma być w przyszłości karta graficzna, ale w kontekście gier 3D, a szczególnie dem 3D wyeliminowanie problemu przepustowości wykorzystując RTG raczej należy rozważać w przypadku nowych produkcji, które ewentualnie powstaną i marginalnej części softu, który już powstał lata temu i potrafi wykorzystać RTG - istniejące dema korzystające z RTG można policzyć na palcach.
Mogę się zgodzić, że w karcie do A500 temat być może nie jest warty poświęcania na niego czasu, ale uważam, że przy karcie WARP1260 zdecydowanie warto, bo ogromna biblioteka istniejących dem 3D może dzięki takiemu rozwiązaniu zyskać całkowicie nową jakość...
W PAL obraz ma 312 rasterlinii więc tą techniką uzyskuje się ok. 112-132 rasterlinii, w czasie których wykonuje się kopiowanie Fast->Chip. Transfer w tym czasie Fast->CPU->Chip określany jest jako 3xCopyspeed ponieważ dla CPU w tym czasie dostępnych jest więcej slotów DMA. Niestety nadal są to sloty taktowane 3,5MHz, a biorąc pod uwagę, że zapis do Chip wymaga dwóch cykli DMA (1 adresowanie, 2 zapis) to efektywna częstotliwość zapisu do Chip jednego długiego słowa (32 bit) jest jeszcze o połowę mniejsza niż taktowanie slotów DMA.
Jednak największym problemem z punktu widzenia CPU jest to, że w tym czasie CPU nie może robić nic innego jak tylko kopiowanie Fast->Chip, a jest to mniej więcej 30-40% czasu ramki! To są bardzo duże straty na wydajności procesora i wydaje się, że przedstawiony przeze mnie pomysł pozwoliłby całkowicie wyeliminować te straty.
Oczywiście na kartach od CS-LAB ma być w przyszłości karta graficzna, ale w kontekście gier 3D, a szczególnie dem 3D wyeliminowanie problemu przepustowości wykorzystując RTG raczej należy rozważać w przypadku nowych produkcji, które ewentualnie powstaną i marginalnej części softu, który już powstał lata temu i potrafi wykorzystać RTG - istniejące dema korzystające z RTG można policzyć na palcach.
Mogę się zgodzić, że w karcie do A500 temat być może nie jest warty poświęcania na niego czasu, ale uważam, że przy karcie WARP1260 zdecydowanie warto, bo ogromna biblioteka istniejących dem 3D może dzięki takiemu rozwiązaniu zyskać całkowicie nową jakość...


12.12.2018 10:51
[#429]
Re: A500 Turbo ..... inaczej
@dante, post #427
Całkiem sporo dem w "060" chodzi pod RTG. I tutaj dopiero będzie można wycisnać 100% z CPU, zwłaszcza że pamięć RTG będzie dostępna bezpośrednio bez spowalniacza zwanego Zorro  . W podobnej sytuacji jest zresztą Vampire, różnica jest tylko taka że.... po przerzuceniu całego chipsetu do FPGA to chipram może być duuużżżżoooo szybszy
. W podobnej sytuacji jest zresztą Vampire, różnica jest tylko taka że.... po przerzuceniu całego chipsetu do FPGA to chipram może być duuużżżżoooo szybszy 
Ostatnia aktualizacja: 12.12.2018 10:56:15 przez pisklak
Ostatnia aktualizacja: 12.12.2018 10:56:15 przez pisklak
12.12.2018 10:52
[#430]
Re: A500 Turbo ..... inaczej
@Paxo, post #426
Pamiętam, dlatego przedstawiam tylko pomysł jako ewentualny temat do zastanowienia się nad tym i podyskutowania na forum. Nie naciskam i nie oczekuję cudów, ale skoro architektura nowych kart jest dzięki zastosowaniu FPGA elastyczna to może chłopaki sami uznają, że taki feature jest warty tego żeby się nad tym kiedyś zastanowić i wrzucić to na roadmapę rozwoju kart.
12.12.2018 10:53
[#431]
Re: A500 Turbo ..... inaczej

@dante, post #424
Konwersja Chunky-Planar nie jest problemem dla Amigi. Problemem jest obsługa przez procesor odpowiedniej liczby pikseli (81920 dla LORES)!
Po prostu procesor 68030 fizycznie nie wyrobi, żeby generować obraz składający się z takiej puli pikseli w 50 FPS. Procesor musi przerabiać 4096000 pikseli na sekundę!
Dlatego należy zmniejszyć tę pulę (np. 40960 albo 20480). Wtedy spokojnie da radę.
Na dowód Doom chodzi z c2p szybciej niż na analogicznym PC.
Problemem nie jest pamięć CHIP, ani magistrala, która jest odpowiednio wydajna, ani c2p.
Po prostu procesor 68030 fizycznie nie wyrobi, żeby generować obraz składający się z takiej puli pikseli w 50 FPS. Procesor musi przerabiać 4096000 pikseli na sekundę!
Dlatego należy zmniejszyć tę pulę (np. 40960 albo 20480). Wtedy spokojnie da radę.
Na dowód Doom chodzi z c2p szybciej niż na analogicznym PC.
Problemem nie jest pamięć CHIP, ani magistrala, która jest odpowiednio wydajna, ani c2p.


12.12.2018 12:28
[#434]
Re: A500 Turbo ..... inaczej
@dante, post #433
Naprawdę, bez obrazy, Dante, ale mylisz się. Jest bardzo dużo produkcji 68K działających na AGA *lub* RTG. Żeby wymienić pierwsze z brzegu - wszystkie produkcje Elude (ja mam dysku 10 z nich), Dekadence (co najmniej 3), Ephidrena (8 produkcji), produkcje Appendix, Loonies, Supergroup, MaWi, Venus Art, RNO... I to jeszcze nie koniec listy. Żadna z tych produkcji nie jest "wątpliwej jakości", każda potrafi otworzyć ekran RTG (zdecydowana większość automatycznie, mały odsetek z pomocą ModePro).
12.12.2018 13:09
[#435]
Re: A500 Turbo ..... inaczej
@skipp, post #434
Vampire GOLD2: RTG Demos - 33 sztuki 68K+RTG, a nie wszystkie jeszcze zdążyłem nagrać.
12.12.2018 13:25
[#436]
Re: A500 Turbo ..... inaczej

@dante, post #424
Pomysłów można mieć mnóstwo, zwłaszcza patrząc jakie mamy teraz możliwości.
Ja np. się zastanawiam, jak zrobić CHIP jako dual-port - wtedy cpu mogłoby sobie w nim śmigać, a wszystkie DMA używałyby drugiego portu. I takie DMA bitplanów, które tylko czyta z CHIP, ciągłoby sobie dane nie spowalniając procka nawet przy 6, czy tam 8 bitplanach.
Ja np. się zastanawiam, jak zrobić CHIP jako dual-port - wtedy cpu mogłoby sobie w nim śmigać, a wszystkie DMA używałyby drugiego portu. I takie DMA bitplanów, które tylko czyta z CHIP, ciągłoby sobie dane nie spowalniając procka nawet przy 6, czy tam 8 bitplanach.
12.12.2018 13:38
[#438]
Re: A500 Turbo ..... inaczej
@Hexmage960, post #431
Nigdzie nie napisałem, że c2p jest problemem dla Amigi!
Zgodzę się, że Chip Ram i magistrala jest odpowiednio wydajna, ale pod warunkiem, że mówimy wyłącznie o zastosowaniach do których były one konstruowane.
Takim zastosowaniem na pewno nie były gry i dema 3D, dlatego uważam (i jestem pewien, że nie tylko ja), że do tych zastosowań ich wydajność jest niestety żenująca. Z racji tego, że mam jakieś tam doświadczenie w kodowaniu dem 3D z epoki świetności demosceny Amigowej i znam bardzo dobrze problemy z jakimi osobiście się borykałem jako koder, a nie lubię ciągle narzekać to pozwoliłem sobie przedstawić pomysł jaki od dawna chodził mi po głowie na to co by ewentualnie można było z tym zrobić, skoro pojawił się temat nowych, wypasionych kart turbo do Amigi...
Pozwolę więc sobie na przytoczenie jeszcze kilka faktów (dla jasności odnoszę się do CPU 060, a nie 030):
1. Przy odświeżaniu 50 FPS jedna ramka trwa 20 ms.
2. Sama konwersja c2p obrazu 320x256x8 (LORES 256 kolorów) na 060@50MHz trwa ok. 5 ms (odczyt z Fast Ram i c2p na rejestrach bez zapisu do Chip Ram)
3. Oznacza to, że Amiga z 060@50MHz może wykonać samo c2p takiego obrazu (bez zapisu do pamięci Chip) z prędkością ok. 200 FPS!
4. Ze względu na to, że wynik konwersji c2p musi jednak być zapisany do Chip Ram, kompletna operacja c2p takiego obrazu zajmuje ok 500 rasterlinii czyli jakieś 1,6 ramki czyli jakieś 32ms
5. Wynika z tego, że sam zapis do Chip Ram spowalnia całą procedurę minimum 6,5 krotnie
6. To z kolei oznacza, że na Amidze z 060@50MHz kompletny c2p (z zapisem do Chip Ram) 'statycznego' obrazu może osiągnąć maksymalnie prędkość 31,25 FPS - 'statycznego' dlatego, że CPU nie ma możliwości robienia niczego innego w tym czasie gdyż 'po korek' zapchany jest 'konwersją' (ekhmm - oczywiście nie konwersją tylko czekaniem na sloty DMA!)
Samo policzenie 3D w Doom'ie to dla takiego procka pewnie spadek o jakieś dodatkowe 10 FPS w wyniku czego na 060@50MHz taki Doom poleci pewnie 20-kilka FPS. Natomiast czy w związku z tym Doom chodzi szybciej czy wolniej niż na 'analogicznym PC' absolutnie mnie nie interesuje.
Generalnie chciałbym uciąć temat c2p w tym wątku bo nie chodziło mi o samą wydajność c2p tylko wskazanie, że w tym czasie CPU się 'marnuje' czekając na dostępy do Chip Ram. Zainteresowanych dalszym drążeniem tematu c2p odsyłam do wątku Which is the fastest software C2P 1x1 routine. Mniej zainteresowanym zacytuję Kalmsa "The C2P transform itself does not take a lot of time (it takes about 4-5ms on a 50MHz 68060 for 320x256 pixels @ 8bpl); bulk of time disappears in fast->chip copying today, so that is where your efforts would make a bigger impact."
Podsumowując, jeśli w teorii pojawia się możliwość zrobienia czegoś 'inaczej' co potencjalnie może pozwolić wykorzystać moc procesora na maksa w większości aktualnie dostępnego softu (w szczególności dem 3D) to gdzie rzucać takie pomysły jak nie tutaj?
Zgodzę się, że Chip Ram i magistrala jest odpowiednio wydajna, ale pod warunkiem, że mówimy wyłącznie o zastosowaniach do których były one konstruowane.
Takim zastosowaniem na pewno nie były gry i dema 3D, dlatego uważam (i jestem pewien, że nie tylko ja), że do tych zastosowań ich wydajność jest niestety żenująca. Z racji tego, że mam jakieś tam doświadczenie w kodowaniu dem 3D z epoki świetności demosceny Amigowej i znam bardzo dobrze problemy z jakimi osobiście się borykałem jako koder, a nie lubię ciągle narzekać to pozwoliłem sobie przedstawić pomysł jaki od dawna chodził mi po głowie na to co by ewentualnie można było z tym zrobić, skoro pojawił się temat nowych, wypasionych kart turbo do Amigi...
Pozwolę więc sobie na przytoczenie jeszcze kilka faktów (dla jasności odnoszę się do CPU 060, a nie 030):
1. Przy odświeżaniu 50 FPS jedna ramka trwa 20 ms.
2. Sama konwersja c2p obrazu 320x256x8 (LORES 256 kolorów) na 060@50MHz trwa ok. 5 ms (odczyt z Fast Ram i c2p na rejestrach bez zapisu do Chip Ram)
3. Oznacza to, że Amiga z 060@50MHz może wykonać samo c2p takiego obrazu (bez zapisu do pamięci Chip) z prędkością ok. 200 FPS!
4. Ze względu na to, że wynik konwersji c2p musi jednak być zapisany do Chip Ram, kompletna operacja c2p takiego obrazu zajmuje ok 500 rasterlinii czyli jakieś 1,6 ramki czyli jakieś 32ms
5. Wynika z tego, że sam zapis do Chip Ram spowalnia całą procedurę minimum 6,5 krotnie
6. To z kolei oznacza, że na Amidze z 060@50MHz kompletny c2p (z zapisem do Chip Ram) 'statycznego' obrazu może osiągnąć maksymalnie prędkość 31,25 FPS - 'statycznego' dlatego, że CPU nie ma możliwości robienia niczego innego w tym czasie gdyż 'po korek' zapchany jest 'konwersją' (ekhmm - oczywiście nie konwersją tylko czekaniem na sloty DMA!)
Samo policzenie 3D w Doom'ie to dla takiego procka pewnie spadek o jakieś dodatkowe 10 FPS w wyniku czego na 060@50MHz taki Doom poleci pewnie 20-kilka FPS. Natomiast czy w związku z tym Doom chodzi szybciej czy wolniej niż na 'analogicznym PC' absolutnie mnie nie interesuje.
Generalnie chciałbym uciąć temat c2p w tym wątku bo nie chodziło mi o samą wydajność c2p tylko wskazanie, że w tym czasie CPU się 'marnuje' czekając na dostępy do Chip Ram. Zainteresowanych dalszym drążeniem tematu c2p odsyłam do wątku Which is the fastest software C2P 1x1 routine. Mniej zainteresowanym zacytuję Kalmsa "The C2P transform itself does not take a lot of time (it takes about 4-5ms on a 50MHz 68060 for 320x256 pixels @ 8bpl); bulk of time disappears in fast->chip copying today, so that is where your efforts would make a bigger impact."
Podsumowując, jeśli w teorii pojawia się możliwość zrobienia czegoś 'inaczej' co potencjalnie może pozwolić wykorzystać moc procesora na maksa w większości aktualnie dostępnego softu (w szczególności dem 3D) to gdzie rzucać takie pomysły jak nie tutaj?
12.12.2018 13:56
[#439]
Re: A500 Turbo ..... inaczej
@marianoamigo, post #437
Nadal demka nawet 30 fps nie osiagaja... czekamy na Warpa 060!
Obejrzałeś już wszystkie, lol? Kolego, nie generalizowałbym, bo niektóre (np. produkcje Supergroup) mają lekko 60fps, niektóre mają "fps cap" ustawiony na 50 (bo PAL/AGA - vide RNO "Software"), a z kolei niektóre były nagrywane z dość starych rdzeni (z "rozwojową" wersją FPU, z zegarem 78MHz, itd.) - rozrzut czasowy jest spory.
To rzekłszy, ja również bardzo jestem ciekaw, jak Warp060 + RTG będzie sobie z nimi radził (nie oczekiwałbym jednak cudów). Bardzo kibucuję dżentelmenom z CS-Lab. Im więcej sprzętu do oglądania amigowych dem, tym lepiej <3
Ostatnia aktualizacja: 12.12.2018 13:58:04 przez skipp
12.12.2018 14:02
[#441]
Re: A500 Turbo ..... inaczej
@skipp, post #439
Tak, na bieżąco jestem z demosceną.... widać straszną nierówność w płynności efektów. Sądzę, żę problemem w tym przypadku (RTG), jest nadal ZBYT mała moc procka 68K w interpretacji Vampira.
Tak jak piszesz - zobaczymy jak 060 z szybką pamięcią będzie się zachowywać. Tak czy siak, na granicy 100Mhz procka się zatrzymamy.
Tak jak piszesz - zobaczymy jak 060 z szybką pamięcią będzie się zachowywać. Tak czy siak, na granicy 100Mhz procka się zatrzymamy.
12.12.2018 14:05
[#442]
Re: A500 Turbo ..... inaczej
@skipp, post #434
Skipp: przyznaję się, mam tendencję do przesadzania... choć nie takie były moje intencje.
W żadnym wypadku nie uważam tych grup czy ich produkcji za 'wątpliwej jakości' bardziej chodziło mi o to, że patrząc z perspektywy całego dorobku sceny Amigowej, to mimo wszystko istniejących produkcji działających pod RTG jest niewiele w stosunku do takich które tego nie potrafią. np. żadna z moich nie potrafi, a prawie wszystkie są spod szyldu Appendix
Ostatnia aktualizacja: 12.12.2018 14:07:35 przez dante
W żadnym wypadku nie uważam tych grup czy ich produkcji za 'wątpliwej jakości' bardziej chodziło mi o to, że patrząc z perspektywy całego dorobku sceny Amigowej, to mimo wszystko istniejących produkcji działających pod RTG jest niewiele w stosunku do takich które tego nie potrafią. np. żadna z moich nie potrafi, a prawie wszystkie są spod szyldu Appendix
Ostatnia aktualizacja: 12.12.2018 14:07:35 przez dante
12.12.2018 15:38
[#443]
Re: A500 Turbo ..... inaczej
@marianoamigo, post #441
Myślę, że niekoniecznie jest to wina "małej mocy" 68K, wydaje mi sie akurat, że 080@78MHz bije 060@100MHz (mogę się mylić). Z ciekawości, bo nigdy nie widziałem - jaki wynik SysInfo daje 060/100MHz? 100MIPS będzie? Jaki wynik pokazuje "Bustest FAST"? Mój Vampire 78MHz daje takie wyniki:
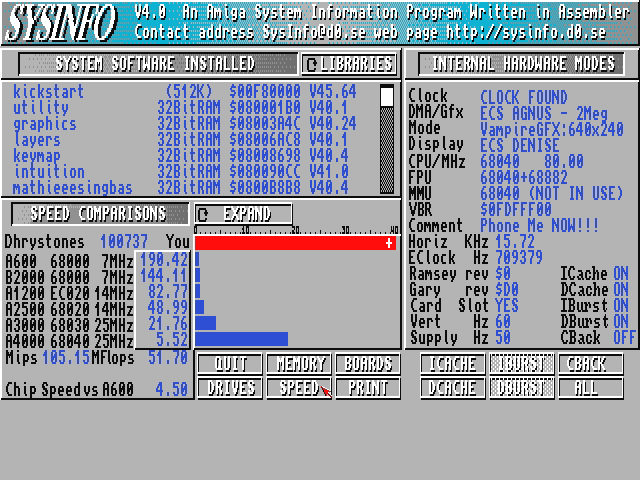
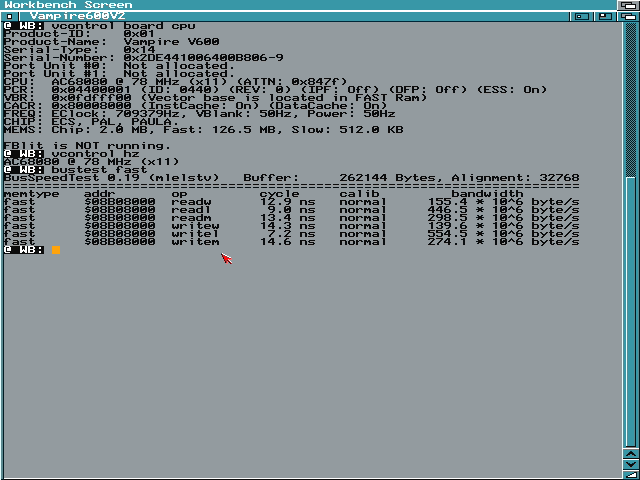
Myślę, że jak na 78MHz to całkiem OK?
Bardzo liczę na to, że Warp060 będzie także dzięki swojej szybkiej pamięci popierniczał aż miło :) I nie mam porównania, ponownie, ale możliwe, że VA2000 jest szybszym RTG od tego, co ma Vampire? Ma ktoś jakieś liczby z VA2000?
EDIT: Znalazłem wyniki 100MHz 060 ;) 132 MIPS, milutko :)
68060 na 100MHz w A4000
EDIT2: Tu "tylko" 77MIPS. Co jest prawdą? :O Jestem skonfudowany.

Ostatnia aktualizacja: 12.12.2018 15:47:12 przez skipp
Myślę, że jak na 78MHz to całkiem OK?
Bardzo liczę na to, że Warp060 będzie także dzięki swojej szybkiej pamięci popierniczał aż miło :) I nie mam porównania, ponownie, ale możliwe, że VA2000 jest szybszym RTG od tego, co ma Vampire? Ma ktoś jakieś liczby z VA2000?
EDIT: Znalazłem wyniki 100MHz 060 ;) 132 MIPS, milutko :)
68060 na 100MHz w A4000
EDIT2: Tu "tylko" 77MIPS. Co jest prawdą? :O Jestem skonfudowany.
Ostatnia aktualizacja: 12.12.2018 15:47:12 przez skipp
12.12.2018 15:46
[#444]
Re: A500 Turbo ..... inaczej
@skipp, post #443
Syntetyczne testy, zwlaszcza ze porownujemy procek w technologii FPGA ze zwykłym, nie przekladają się na realne odczucia... Vampire ma potężny transfer pamięci RAM, a w demkach tego nie widać, działa jak szybka 060, widać musi część zużywać na potrzeby wewnętrzej emulacji.
Myślę że celem nowego turbo jest po prostu dojechanie Falcona z CT63
Myślę że celem nowego turbo jest po prostu dojechanie Falcona z CT63
12.12.2018 16:44
[#445]
Re: A500 Turbo ..... inaczej
@Paxo, post #426
No brawo ktoś to widzę rozumie . Na dodatek FPGA zajmuje się tylko Andrzej a robi to jeszcze tak naprawdę poza czasem pracy gdzie zajmuje się programowaniem. Tak wiec pomysły fajne pewnie w niektórych przypadkach dało by kopa. Sam zastanawiałem się nad zrobieniem sprzętowego kanału do chip ramu ale stwierdziliśmy ze poprostu szkoda teraz na to czasu i najważniejsze jest odpalenie RTG na tych kartach. Bo jeszcze i tak jest dużo pracy z innymi peryferiami !
A no i masz całkowicie racje nikt jeszcze do pomocy się nie odezwał ! A oczekiwania Zorro..PPC... i kto wie co jeszcze
Apollo Team a jak by było po angielsku CS-Lab Duet czy może lepiej CS-Lab one person ?? Nie wiem co ładniej brzmi
Ostatnia aktualizacja: 12.12.2018 16:51:42 przez Cizar
Ostatnia aktualizacja: 12.12.2018 17:00:37 przez Cizar
A no i masz całkowicie racje nikt jeszcze do pomocy się nie odezwał ! A oczekiwania Zorro..PPC... i kto wie co jeszcze
Apollo Team a jak by było po angielsku CS-Lab Duet czy może lepiej CS-Lab one person ?? Nie wiem co ładniej brzmi
Ostatnia aktualizacja: 12.12.2018 16:51:42 przez Cizar
Ostatnia aktualizacja: 12.12.2018 17:00:37 przez Cizar
12.12.2018 16:50
[#446]
Re: A500 Turbo ..... inaczej
@skipp, post #443
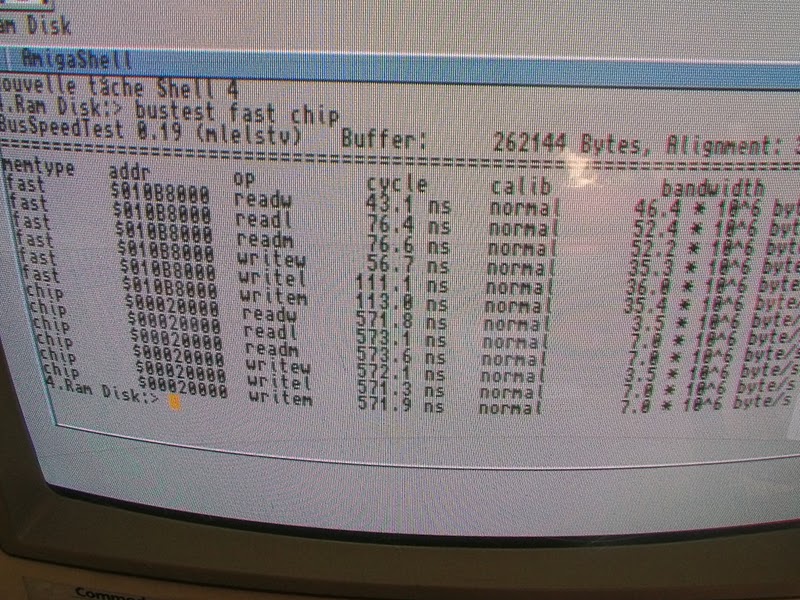
Nie mam jak teraz sprawdzić bo Amigę mam chwilowo rozbebeszoną, ale z tego co pamiętam to zarówno na Apollo 1260@80MHz jak i na Blizzard 1260@80MHz mam powyżej 100 MIPS - nie pamiętam tylko czy w SysInfo czy SysSpeed.
Druga sprawa czy bustest odpalasz po 'cpu nodatacache'? Jeśli nie wyłączasz cache danych to wyniki do fastu będziesz miał mocno zawyżone.
Akurat mam pod ręką zrzuty z bustest'a zrobione na moim Blizzard 1260@80MHz.
z włączonym Data Cache:
bez Data Cache:
Druga sprawa czy bustest odpalasz po 'cpu nodatacache'? Jeśli nie wyłączasz cache danych to wyniki do fastu będziesz miał mocno zawyżone.
Akurat mam pod ręką zrzuty z bustest'a zrobione na moim Blizzard 1260@80MHz.
z włączonym Data Cache:
BusSpeedTest 0.19 (mlelstv) Buffer: 262144 Bytes, Alignment: 32768 ======================================================================== memtype addr op cycle calib bandwidth fast $68098000 readw 40.4 ns normal 49.6 * 10^6 byte/s fast $68098000 readl 70.5 ns normal 56.7 * 10^6 byte/s fast $68098000 readm 70.3 ns normal 56.9 * 10^6 byte/s fast $68098000 writew 51.6 ns normal 38.7 * 10^6 byte/s fast $68098000 writel 101.3 ns normal 39.5 * 10^6 byte/s fast $68098000 writem 102.2 ns normal 39.1 * 10^6 byte/s chip $00018000 readw 892.9 ns normal 2.2 * 10^6 byte/s chip $00018000 readl 893.5 ns normal 4.5 * 10^6 byte/s chip $00018000 readm 893.0 ns normal 4.5 * 10^6 byte/s chip $00018000 writew 572.9 ns normal 3.5 * 10^6 byte/s chip $00018000 writel 573.3 ns normal 7.0 * 10^6 byte/s chip $00018000 writem 573.5 ns normal 7.0 * 10^6 byte/s
bez Data Cache:
BusSpeedTest 0.19 (mlelstv) Buffer: 262144 Bytes, Alignment: 32768 ======================================================================== memtype addr op cycle calib bandwidth fast $68098000 readw 154.8 ns normal 12.9 * 10^6 byte/s fast $68098000 readl 152.5 ns normal 26.2 * 10^6 byte/s fast $68098000 readm 134.5 ns normal 29.7 * 10^6 byte/s fast $68098000 writew 140.8 ns normal 14.2 * 10^6 byte/s fast $68098000 writel 140.9 ns normal 28.4 * 10^6 byte/s fast $68098000 writem 102.4 ns normal 39.1 * 10^6 byte/s chip $00018000 readw 898.4 ns normal 2.2 * 10^6 byte/s chip $00018000 readl 899.4 ns normal 4.4 * 10^6 byte/s chip $00018000 readm 900.2 ns normal 4.4 * 10^6 byte/s chip $00018000 writew 674.0 ns normal 3.0 * 10^6 byte/s chip $00018000 writel 673.0 ns normal 5.9 * 10^6 byte/s chip $00018000 writem 579.7 ns normal 6.9 * 10^6 byte/s

12.12.2018 18:51
[#448]
Re: A500 Turbo ..... inaczej
@skipp, post #443
Bardzo liczę na to, że Warp060 będzie także dzięki swojej szybkiej pamięci popierniczał aż miło :) I nie mam porównania, ponownie, ale możliwe, że VA2000 jest szybszym RTG od tego, co ma Vampire? Ma ktoś jakieś liczby z VA2000?
VA2000 jako kart na ZORRO nie ma szans być szybsza, bo Zorro jest wąskim gardłem (na 030 50MHz chyba coś koło 13MB/s max :-/). Ale takie VA na karcie chłopaków ma prawo być sporo szybsze, bo komunikacja będzie się odbywać wewnętrznie.
12.12.2018 19:09
[#449]
Re: A500 Turbo ..... inaczej
@flops, post #448
Tak naprawdę to nie będzie kropla w krople VA2000 choćby dlatego ze :
- pamięć zastosowana jest inna niż VA2000
- magistrala połączenia jest inna w obu przypadkach
- układ FPGA jest inny ( Spartan vs Artix)
Tak naprawdę VA2000 będzie dla nas zaczepieniem w stworzeniu własnej karty , pisaniu drivera .. itp. Karta tutaj zostanie stworzona jako nowy inny projekt. Poza tym porównywanie kart WARP vs APOLLO to wielkie nieporozumienie to zupełnie inne konstrukcje ! wiec z szacunku dla autorów obydwu kart proszę o cisze na forum dla przekomarzania można sobie założyć osobny post.
- pamięć zastosowana jest inna niż VA2000
- magistrala połączenia jest inna w obu przypadkach
- układ FPGA jest inny ( Spartan vs Artix)
Tak naprawdę VA2000 będzie dla nas zaczepieniem w stworzeniu własnej karty , pisaniu drivera .. itp. Karta tutaj zostanie stworzona jako nowy inny projekt. Poza tym porównywanie kart WARP vs APOLLO to wielkie nieporozumienie to zupełnie inne konstrukcje ! wiec z szacunku dla autorów obydwu kart proszę o cisze na forum dla przekomarzania można sobie założyć osobny post.